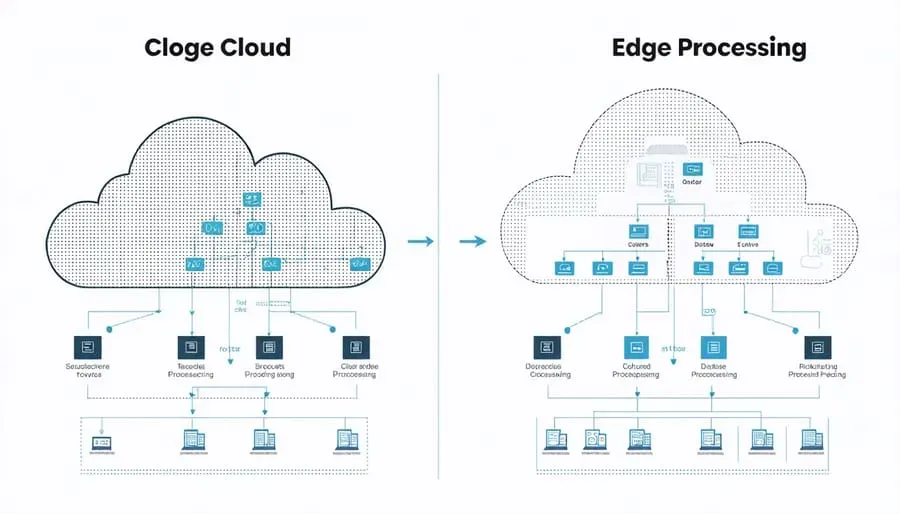
Cloud vs Edge data processing is redefining how organizations design responsive, scalable IT systems in an era of exploding device-generated data. By processing near the data source, edge computing minimizes latency and contributes to latency reduction, enabling real-time data processing for time-sensitive tasks. In contrast, cloud computing vs edge computing offers vast scale, sophisticated analytics, and durable storage, forming the backbone of data processing architectures that support long-term insights. A smart hybrid approach blends both paradigms, delivering rapid responses where latency matters and deep analytics at scale where it does not. Understanding when to push work to the edge, when to migrate to the cloud, and how to orchestrate data flows is essential for modern IT resilience.
Beyond the familiar cloud-versus-edge framing, this topic invites a look at near-source computing, where data is processed close to its origin. LSI-inspired terms such as edge-native analytics, on-device processing, and localized inference help describe how modern architectures distribute work across devices, gateways, and public or private clouds. This distributed approach still centers on balancing speed and depth of insight, but it emphasizes locality, governance, and resilient connectivity. As organizations adopt hybrid data stacks, the shift is less about choosing one side and more about orchestrating coordinated, layered processing that matches use case requirements.
Cloud vs Edge data processing: understanding the continuum and decision criteria
Cloud vs Edge data processing defines a continuum rather than a binary choice. As organizations collect data from devices, sensors, and apps, the decision of where to compute shapes latency, bandwidth costs, and the speed of decision-making. In this framing, cloud computing vs edge computing is not about choosing one over the other but about orchestrating a coherent data processing architectures that balance central analytics with local responsiveness.
Key decision criteria include latency sensitivity, data volume and velocity, regulatory requirements, offline operation needs, and total cost of ownership. A well-crafted hybrid approach assigns real-time data processing tasks to the edge when milliseconds matter, while moving batch analytics and deep modeling to the cloud.
Real-time data processing at the edge: latency reduction as a driver for edge computing
Real-time data processing at the edge enables immediate actions on sensor streams and device events. By processing data close to the source, organizations achieve faster feedback loops, improved safety, and better user experiences through latency reduction.
Edge-native analytics, streaming filters, and local inference enable autonomous responses, while the cloud handles long-term storage, historical analysis, and model refinement.
Data processing architectures for hybrid cloud and edge deployments
Data processing architectures for hybrid cloud and edge deployments emphasize portability, interoperability, and governance across distributed resources.
A practical hybrid stack combines edge-native analytics for live insights, cloud-centric analytics for scale, and federated analytics to share learning without pooling raw data.
Security, privacy, and governance in cloud and edge environments
Security, privacy, and governance must be embedded at every layer—from device firmware and edge gateways to cloud storage and data pipelines.
Key controls include identity and access management across environments, encryption at rest and in transit, data locality policies, and continuous monitoring to detect threats that span the whole stack.
Industry use cases: cloud and edge data processing in manufacturing, healthcare, and cities
Industry use cases demonstrate the value of cloud and edge data processing across sectors such as manufacturing, healthcare, and smart cities. Edge on the factory floor delivers real-time visibility and predictive maintenance, while the cloud aggregates trends and supports enterprise-wide analytics.
In healthcare wearables and retail experiences, latency-sensitive decisions happen at the edge, with the cloud handling privacy-preserving analytics and broad-scale modeling.
Designing a practical hybrid strategy: patterns, deployment, and orchestration
Designing a practical hybrid strategy starts with choosing deployment patterns, governance, and observability requirements.
Route latency-sensitive workloads to the edge, enable robust data pipelines, and use federated learning and cloud-based model training to continuously improve across the ecosystem.
Frequently Asked Questions
What is Cloud vs Edge data processing and when should you favor edge computing over cloud computing?
Cloud vs Edge data processing describes where data is processed—at the edge or in the cloud. Edge computing minimizes latency and enables real-time data processing by running workloads near data sources, while cloud computing offers scalable analytics and storage for deep insights. Choose edge for time‑critical, bandwidth‑constrained, or offline scenarios; choose the cloud for heavy analytics, model training, and long‑term data storage. Many organizations blend both to balance speed and insight.
How does latency reduction influence decisions in Cloud vs Edge data processing?
Latency reduction is a primary driver in Cloud vs Edge data processing. Edge computing lowers round‑trip time, enabling real‑time or near real‑time actions, which is crucial for applications like automation and control systems. The cloud excels at complex analytics and large‑scale processing but introduces more delay. A hybrid approach places latency‑sensitive tasks at the edge while reserving cloud resources for deeper analysis and historical insights.
What data processing architectures are typical in Cloud vs Edge data processing?
Common architectures include edge‑native analytics for immediate insights at the source, cloud‑centric analytics for heavy processing and model training, and federated analytics that train models across locations while syncing with the cloud. Data orchestration and governance ensure secure data movement, provenance, and policy compliance across both environments. A layered or hybrid architecture often delivers the best balance of speed and depth of insight.
What security considerations matter in Cloud vs Edge data processing?
Security must span both edge and cloud environments in Cloud vs Edge data processing. Key concerns include identity and access management across devices, gateways, on‑premises, and cloud; encryption at rest and in transit with robust key management; secure boot and tamper resistance for edge devices; data locality and governance to satisfy privacy and regulatory requirements; and continuous monitoring and incident response that cover the full data pipeline.
What factors should guide a hybrid Cloud vs Edge data processing strategy?
Guide decisions by latency tolerance, data volume and type, privacy and data sovereignty, cost and bandwidth, resilience/offline capability, and available skills and tooling. A practical approach uses edge pre‑processing for latency‑sensitive workloads and a cloud layer for deep analytics, model training, and archival. Data orchestration and governance tie the stack together to ensure consistent, compliant results across environments.
Can you share real-world use cases that illustrate Cloud vs Edge data processing advantages?
Industrial automation uses edge for real‑time anomaly detection on the factory floor while the cloud aggregates data for long‑term trends. Smart cities rely on edge for local alerts and the cloud for city‑wide analytics. Healthcare wearables process data at the edge to protect privacy, with the cloud storing de‑identified data for research. Retail and autonomous systems illustrate the blend: edge enables fast decisions, while cloud analytics and updates enable broader insight and learning.
| Topic | Key Points |
|---|---|
| Cloud computing basics: |
• |
| Edge computing basics: |
|
| Latency & real-time data processing: |
|
| Architectures & patterns (hybrid & distributed): |
|
| Benefits & trade-offs (what to optimize): |
|
| Real-world use cases driving decisions: |
|
| Security, governance & risk management: |
|
| Decision framework (cloud/edge/hybrid): |
|
| Operational considerations (deployment & governance): |
|
| Future trends & implications: |
|
Summary
Cloud vs Edge data processing is a continuum, not a fixed all-or-nothing choice. The most effective strategies blend the strengths of both paradigms to deliver speed where it matters and depth of insight at scale. Start by identifying latency-sensitive use cases and governance requirements, then design a hybrid architecture that routes appropriate workloads to the edge while leveraging cloud analytics for long-term insights. This approach supports real-time decision-making, optimized bandwidth, and robust security across distributed data landscapes. As patterns evolve, innovations like AI at the edge, federated learning, and intelligent gateways will further tighten the integration between edge and cloud, enabling organizations to build resilient, scalable architectures that adapt to changing business needs.